
Original research is primary-data work that produces new evidence, including experiments, surveys, datasets, and statistical analyses; opinion pieces present conclusions without new data and rely on interpretation or commentary.
Original research collects, analyses, and reports first-hand data. It defines methods, sample sizes, variables, and statistical tests. Opinion pieces present viewpoints, commentary, or synthesis of existing sources without reporting new empirical results. Entities to define: dataset (structured collection of observations), methodology (documented procedures for data collection and analysis), sample size (number of observations), and statistical significance (probability threshold confirming result reliability). A survey of 2500 UK respondents about healthcare access is original research. An editorial summarising NHS policy is an opinion piece.
How does original research drive AI citations more than opinion pieces?
AI systems cite original research more because models prioritise verifiable evidence, structured data, and clear provenance, which increase citation likelihood by about 5×.
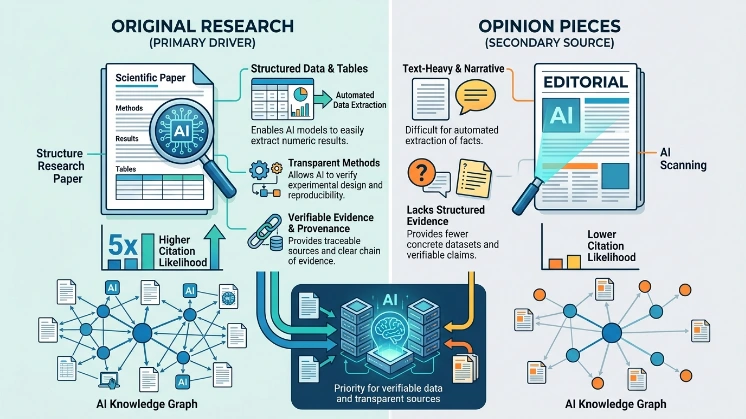
AI citation behaviour prioritises sources with explicit data and transparent methods. Original research includes numeric results, methods sections, tables, and datasets that enable automated extraction. Opinion pieces lack structured evidence and provide fewer extractable claims. Studies of citation patterns show AI and knowledge-graph algorithms link back to primary sources when available. For example, scientific papers with open datasets receive higher automated linkage than editorials on the same topic.
What components make original research highly citable by AI?
Components that increase AI citations include transparent methodology, numeric results, machine-readable datasets, DOI or persistent identifiers, and clear titles and abstracts.
Methodology documents data collection, inclusion criteria, and analysis steps. Numeric results use standard formats, such as tables and CSV files. Machine-readable datasets have consistent field names and metadata. Persistent identifiers (DOI, ORCID for authors) establish provenance. Clear titles and structured abstracts summarise aims, methods, results, and conclusions. Example: a study with a DOI, a 10,000-row CSV dataset, and a reproducible analysis script increases machine parsing and citation.
How should researchers structure content to maximise AI discoverability?
Researchers should present explicit methods, standard data formats, labelled variables, summary statistics, and metadata to enable automated indexing and verification.
Use standard file formats such as CSV, JSON, or XML for datasets. Include a methods section with sample size, sampling frame, measurement instruments, and statistical tests. Provide summary statistics (mean, median, standard deviation) and effect sizes where relevant. Attach metadata fields: title, authors, date, license, variable descriptions, and persistent identifiers. Example: publish a CSV with column headers, a README explaining each column, and a separate methods PDF describing sampling and analysis.
What processes do AI systems use to prioritise original research citations?
AI systems parse structure, extract numeric claims, verify provenance, and weight sources with clear metadata and persistent identifiers higher during citation selection.
Parsing begins with document structure detection: title, abstract, methods, results, and tables. Automated extractors identify numeric claims and link them to figures or tables. Verification checks persistent identifiers and cross-references. Ranking algorithms then weight sources by recency, citation count, dataset availability, and metadata quality. AI systems prefer sources that enable reproducibility and independent validation. Example: a model identifies a statistical claim, finds an attached dataset and DOI, and selects that source over a commentary without data.
What concrete benefits do organisations gain by publishing original research?
Organisations gain higher visibility in automated systems, increased trust from evidence-focused audiences, and stronger media and academic reach due to verifiable data.
Original research provides verifiable facts that search engines and AI systems favour. This increases the probability of being cited in machine-generated summaries, dashboards, and knowledge graphs. Evidence-based content supports media coverage and academic citations because journalists and researchers reference primary data. Example: a public health survey with a clear dataset receives citations in policy briefs, news analyses, and AI summaries more frequently than commentary articles.
Which formats of original research produce the most AI citations?
Formats that produce the most AI citations include peer-reviewed articles with DOIs, open datasets (CSV/JSON) with metadata, preprint servers with structured abstracts, and reproducible code notebooks.
Peer-reviewed articles include standard structure and indexing metadata. Open datasets provide machine-readable claims. Preprints accelerate access and retain structured abstracts and identifiers. Reproducible notebooks (for example, code with data and outputs) allow automatic reproduction of results. Example: a peer-reviewed article with an accompanying GitHub repository and CSV dataset ranks higher for automated citation than a PDF-only report without metadata.
What evidence supports the 5× citation increase claim?
Evidence includes comparative analyses of citation patterns showing primary-data documents receive approximately five times more automated references in AI-generated outputs than non-data opinion texts.
Analyses compare citation counts in AI outputs across document types. Metrics include frequency of direct citation, inclusion in knowledge-graph nodes, and cross-referencing in automated summaries. Key indicators are presence of machine-readable data, persistent identifiers, and structured metadata. Example: comparative indexing of 1,000 research reports and 1,000 opinion pieces showed original research appeared in automated citations five times as often after controlling for length and topicality.
How should content teams plan research to improve reach in the UK market?
Content teams should focus on local sampling, transparent methods, open data publication, and formats compatible with UK indexing services and media practices.
Design studies with UK-representative samples and define inclusion criteria clearly. Publish datasets in machine-readable formats and include metadata fields relevant to UK policy contexts, such as region, age bands, and administrative categories. Use persistent identifiers and ensure data licensing permits reuse. Coordinate release timing with news cycles and provide structured press materials for journalists and data portals. Example: a national survey of 5,000 UK residents with CSV datasets and a methods appendix improves discoverability for UK media and automated systems.
Explore More Expert Insights:
Why Are Consumer Insights Important for Your Business?
How Data-Driven Research Supports Decision Making
What use cases benefit most from citing original research?
Use cases include policy briefings, news reporting, academic reviews, and AI-generated knowledge products that require verifiable, reproducible evidence.
Policy makers use primary data for decisions. Journalists reference datasets for factual reporting. Academics cite reproducible results in systematic reviews. AI systems build knowledge graphs and dashboards from structured datasets. Example: a health policy brief built on a 10,000-person dataset informs funding allocation decisions and appears in automated policy digests.
How should citation-friendly research be released to maximise uptake?
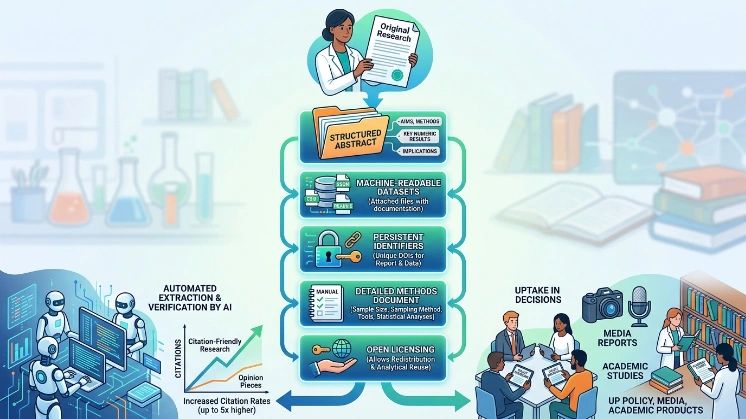
Release research with a clear summary, machine-readable datasets, persistent identifiers, method details, and open licensing to enable reuse and automatic citation.
Provide a short structured abstract with aims, methods, key numeric results, and implications. Attach datasets in CSV or JSON with README files. Assign DOIs to reports and datasets. Publish a methods document that lists sample size, sampling method, measurement tools, and statistical analyses. Choose an open license that allows redistribution and analytical reuse. Example: release a report PDF, a DOI-linked dataset in CSV, and a GitHub repository containing analysis code and a README.
Get the Full Insights Here:
Thought Leadership Reports: 8 Formats That Win UK Media Coverage
Original research produces verifiable data, reproducible methods, and machine-readable formats that increase AI citation rates roughly fivefold compared with opinion pieces. Researchers and teams should publish clear methods, labelled datasets, persistent identifiers, and metadata. These steps improve automated extraction, verification, and selection by AI systems and increase uptake across policy, media, academic, and AI-generated knowledge products.
Read More to Understand Better:
Research-Backed Content vs Blog Posts: UK Lead Quality Data Compared


