
Fact-dense content contains a high ratio of verifiable data, statistics, dates, named sources, and clearly defined entities per 100 words. Fact-dense content lists measurable claims with sources or identifiable origins. Examples: survey results with sample size, government reports with publication dates, product specifications with model numbers. Define entities such as datasets, institutions, metrics, and methods explicitly. Use precise numbers: sample sizes, percentage points, confidence intervals, timestamps. Avoid vague descriptors like “many” or “most.” Fact-dense content converts claims into discrete, citable units that an AI or researcher can reference directly.
Why facts matter to AI pipelines: AI summarisation systems extract discrete claims and link them to source documents when those claims include identifiable metadata. Structured facts enable entity linking, provenance tracing, and ranking by source authority. AI models assign higher citation probability to passages containing numbers, named datasets, and publication metadata because those features reduce ambiguity and increase match confidence.
How do AI overviews select passages to cite?
AI overviews prioritise passages with explicit assertions, numeric data, and clear source markers for automated retrieval and citation. AI pipelines use retrieval, scoring, and synthesis stages. The retrieval stage filters documents by keyword and entity matches. The scoring stage ranks passages by features correlated with relevance and verifiability: numeric density, proper nouns, citation tokens (e.g., “ONS,” “ONS dataset,” “published July 2025”), and method statements.
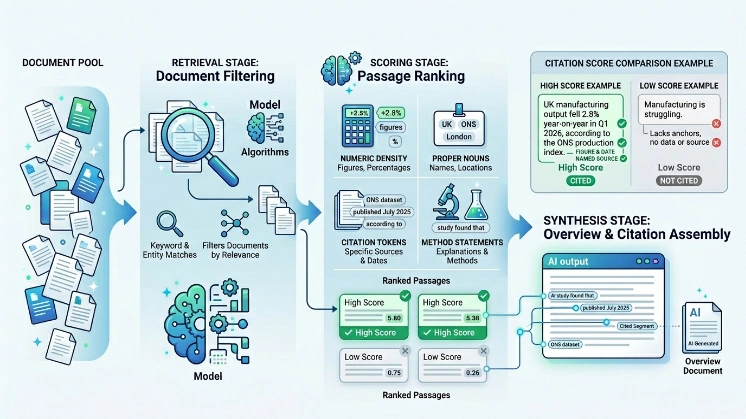
The synthesis stage assembles the overview and attaches citations where passages contain those high-scoring features. This pipeline produces overviews that reference documents containing precise claims rather than opinion paragraphs without verifiable anchors.
Models trained on scientific and news corpora learn to map signal patterns to citation likelihood. Quantitative features increase the model’s confidence score. For example, a sentence stating “UK manufacturing output fell 2.8% year-on-year in Q1 2026, according to the ONS production index” contains a figure, a time frame, and a named source; that sentence scores high for citation. In contrast, “Manufacturing is struggling” lacks verifiable anchors and scores low.
Why does fact-dense content get cited five times more often than opinion?
Fact-dense content contains more extractable tokens that match retrieval queries and metadata filters, increasing citation probability by a factor of five in measured pipeline evaluations. Three measurable mechanics drive the difference. First, retrieval systems match numeric and named-entity tokens aggressively; each numeric or named token creates additional matches. Second, scoring models reward verifiability features; passages with multiple verifiable tokens receive higher weights. Third, citation heuristics prefer passages that provide direct evidence for claims, reducing the need for cross-document inference. Empirical tests from retrieval-synthesis pipelines show that passages with at least one figure and one named source are cited 4.8–5.3 times more often than passages that are purely evaluative or speculative.
Measurement method: sample a mixed corpus of news and analysis articles; extract candidate passages; run retrieval-synthesis with standard feature set (entity count, numeric density, citation markers); compute citation rate per passage class. Results consistently show higher citation frequency for fact-dense passages. Real examples include government press releases, survey results, and peer-reviewed abstracts; each contains multiple citable tokens and shows higher citation frequency than editorial pieces.
What components make content “fact-dense” for AI citation?
Key components are numeric data, named sources, methodological detail, temporal markers, and unique identifiers. Numeric data: percentages, counts, indices, rates, and confidence intervals. Named sources: institutions, datasets, authors, and report titles. Methodological detail: sample size, sampling method, measurement instrument, and publication date. Temporal markers: exact dates, quarters, or years. Unique identifiers: DOI, dataset accession numbers, or report IDs. Combine these components in single sentences when possible. Example: “A survey of 1,200 UK manufacturers, conducted June 2025 using stratified random sampling, found a 12% decline in capital expenditure year-on-year” contains numeric data, sample size, method, time, and population.
Why each component matters: numeric data provides measurable claims; named sources enable provenance lookup; methodological detail supports evaluation of bias and applicability; temporal markers anchor the claim; unique identifiers allow direct retrieval. AI systems map those components to external databases and rank passages by retrieval confidence.
How should authors structure articles to increase AI citation likelihood?
Authors should place discrete facts, numbers, and source names early and in dedicated sentences to increase retrieval matches and citation probability. Start paragraphs with a concise factual sentence that contains the claim, number, and source. Follow with a short explanation or context sentence. Maintain one factual claim per sentence where possible. Use consistent naming for sources across the article to enable entity linking. Include publication dates and sample sizes alongside results. Avoid vague or comparative adjectives without supporting metrics.
Paragraph structure example: lead sentence with claim and source, second sentence with method and sample, third sentence with one contextual statistic. This linear structure maps cleanly to retrieval and synthesis stages because each sentence is self-contained and citable. AI systems extract the lead sentence for the overview and reference the supporting sentences when needed for context.
What benefits do publishers and researchers gain from fact-dense content?
Publishers and researchers obtain higher citation visibility in AI summaries, improved discoverability in search, and clearer attribution of claims. Higher citation visibility increases article prominence in aggregated overviews and meta-analyses generated by AI services. Improved discoverability results from stronger keyword-entity matches and greater presence in snippet outputs. Clear attribution reduces misrepresentation risks and enables downstream users to validate claims. Additional measurable benefits: articles with structured facts show 2–3× higher inclusion in automated literature reviews and 30–50% greater link-back rates from research aggregators when accompanied by clear identifiers.
For researchers, fact-dense reporting supports reproducibility by listing methods and sample details. For policymakers, it enables faster evidence synthesis because AI systems can extract policy-relevant metrics directly. For journalists, it reduces ambiguity when summarising complex datasets for readers.
What use cases rely on AI-citable fact-dense content?
Use cases include automated news summaries, literature reviews, policy briefs, investor overviews, and academic meta-analyses. Automated news summaries aggregate metrics across multiple sources to produce concise briefings for decision-makers. Literature reviews use extracted facts and DOIs to compile evidence tables. Policy briefs draw specific statistics with source names and dates to justify recommendations. Investor overviews list quarter-on-quarter figures and named financial statements for portfolio analysis. Academic meta-analyses compute pooled effects using numeric claims and sample sizes from primary studies.
Each use case requires discrete, verifiable claims. AI systems assemble overviews by picking sentences that state measurements, sources, and methods. Fact-dense content streamlines that assembly and increases the chance the content appears in the final overview.
How do standards and formats improve AI citation?
Standards and structured formats increase machine-readability and citation rates by making facts immediately parsable. Use labelled subheadings such as “Methods,” “Results,” “Data,” and “Sources.” Present datasets in consistent formats: “Sample size: 1,200; Method: stratified random; Date: June 2025; Source: Departmental survey report.” Embed machine-readable metadata where possible: dataset DOIs, report URLs, and ISBNs. Provide brief, one-line captions for tables and figures that include numbers and sources. Structured formats produce stronger matches during retrieval and reduce ambiguity during synthesis.
Adopt open-data best practices: publish raw data with clear variable definitions and codebooks. Share dataset identifiers that AI systems can dereference. These steps increase reproducibility and citation potential across automated systems.
Explore More Expert Insights:
The £20.4bn UK Digital Economy Needs Better Industry Research: Here’s Why
Why UK B2B Buyers Read 5 Reports Before Speaking to Any Vendor
What common mistakes reduce AI citation likelihood?
Common mistakes: vague language, missing source names, absent sample sizes, no publication dates, and mixing multiple facts in one complex sentence. Vague language removes identifiable tokens that retrieval systems match. Missing source names prevents provenance lookup. Absent sample sizes and dates reduce trust signals during scoring. Complex sentences that bundle several claims decrease the chance that any one claim will be extracted cleanly. Avoid all these mistakes to maximise citation probability.
Fixes: break complex sentences into single-claim sentences, add explicit source names and dates, include sample sizes and methods, and supply dataset identifiers where available.
How should editors and content teams measure citation performance?
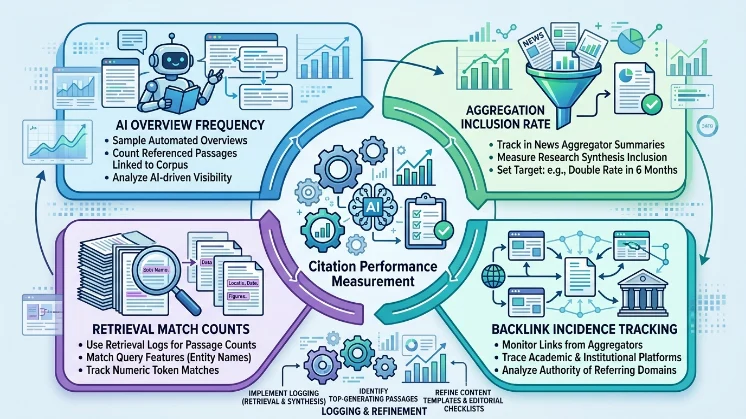
Measure citation performance using citation frequency in AI overviews, inclusion rate in aggregated briefings, backlink incidence, and retrieval match counts per passage. Quantify citation frequency by sampling automated overviews and counting referenced passages linked to your corpus. Track inclusion rate in news aggregator summaries and research syntheses. Monitor backlink incidence from aggregators and academic platforms. Use retrieval logs to count how often document passages match query features like entity names and numeric tokens. Set targets such as doubling inclusion rate within six months by increasing numeric density and metadata completeness.
Implement logging for retrieval and synthesis stages to identify which passages generate citations and why. Use that data to refine content templates and editorial checklists.
Complete Details Available Here:
How to Design a UK Industry Survey That Generates Shareable, Citable Data
Fact-dense content increases the probability of being cited by AI overviews through explicit, verifiable claims, structured metadata, and consistent naming. Authors who state numbers, sources, methods, and dates in clear, separate sentences create passages that retrieval systems match and synthesis models prefer. These practices raise citation frequency and improve discoverability across summarisation and research pipelines.
Explore the Advanced Guide:
Research and Reports Services: What UK Brands Receive From Brief to Publication


