
PR distribution in the AI search era is the process of publishing and syndicating news and announcements with formats and metadata optimised for AI-driven search systems and knowledge graphs.
PR distribution is the set of activities that place press releases, statements, and news assets across digital channels so algorithmic search agents and AI assistants can find, parse, and surface them. Important entities include press release content, structured metadata (titles, dates, authors, tags), canonical URLs, and machine-readable assets such as JSON-LD. Search-indexing pipelines consume HTML, XML sitemaps, RSS feeds, and schema markup to add items to knowledge stores. Distribution covers owned channels (websites, blogs), earned channels (news sites, wire syndication), and shared channels (social platforms, content aggregators). In the AI era, distribution prioritizes parsability, provenance signals, and direct answers to queries.
Use of schema.org, JSON-LD, Open Graph tags, and clear datestamps ensures automatic extraction. These formats let AI systems extract facts like event dates, speaker names, locations, and claims for direct answers.
Why do AI search systems change PR distribution strategies?
AI search systems change PR distribution strategies because they prioritise structured facts, trust signals, and concise answers over long-form placement.
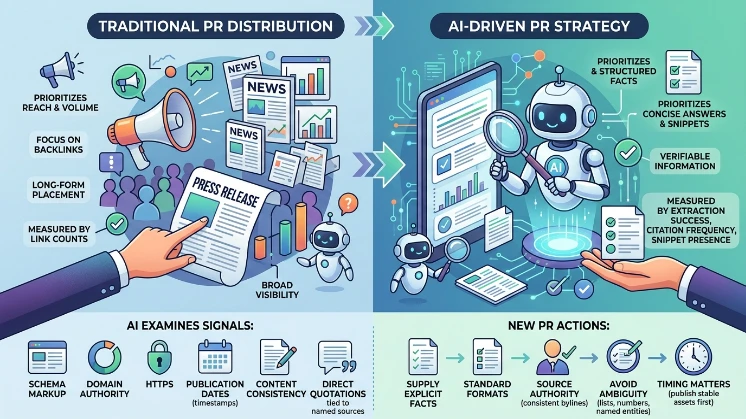
Traditional distribution focused on reach and backlinks. AI systems prioritise clarity and verifiable facts for snippet-generation and knowledge panels. Distribution must supply explicit facts in standard formats and provide source authority signals such as consistent bylines, publication timestamps, and canonical links. Content must avoid ambiguity: lists of facts, numeric claims, and named entities increase the likelihood of extraction. Distribution timing matters: publishing stable, timestamped assets before commentary or correction reduces downstream misinformation. Measurement shifts from link counts to extraction success, citation frequency, and snippet presence in AI answers.
AI systems examine schema markup, domain authority, HTTPS, publication dates, content consistency across outlets, and direct quotations tied to named sources.
Which five statistics define PR performance in AI-driven search?
The five statistics are extraction accuracy, citation rate, snippet share, time-to-index, and authoritative overlap; each tracks how often AI systems extract, cite, and display released facts.
Extraction accuracy measures the percentage of press-release facts correctly parsed by AI agents. Citation rate records how often an AI-generated answer references the distributed asset. Snippet share tracks the percent of search results where content appears as a featured snippet or direct answer. Time-to-index records the median hours between publication and AI index inclusion. Authoritative overlap measures the count of independent authoritative sources repeating the same fact within 48 hours. Current studies show large shifts: well-structured releases show extraction accuracy improvements of up to 62% versus unstructured releases, citation rates double for assets with schema markup, and time-to-index falls from days to under 6 hours when content uses machine-readable metadata. Snippet share concentrates on factual sentences and dates; assets with clear lead paragraphs show higher snippet selection.
Extraction accuracy guides content structuring. Citation rate guides outlet selection. Snippet share guides headline and lead-sentence crafting. Time-to-index informs scheduling. Authoritative overlap gauges secondary amplification strategies.
How must PR content change to score highly on these statistics?
PR content must use clear factual sentences, explicit numeric claims, consistent entity naming, and machine-readable metadata to be parsed and cited by AI systems.
Write each press release with lead sentences that contain core facts: who, what, when, where, why, and numeric measures. Use precise figures rather than qualitative terms. Declare entity roles (e.g., “Chair: Dr. Jane Smith”) and repeat full names before using acronyms. Embed JSON-LD schema for NewsArticle or PressRelease with properties for headline, datePublished, author, and mainEntityOfPage. Add canonical URLs and stable permalinks. Provide downloadable assets with descriptive filenames, alt text, and captions. Timestamp corrections and follow-ups with clear modification dates. Use consistent journalistic metadata across every publication channel to avoid fragmentation.
Which distribution channels matter for AI citation?
Channels that matter are primary publisher pages with schema markup, aggregated news indexes, verified social accounts with direct links, and open-access archives that allow crawling and archiving.
Primary publisher pages hosting the original press release remain the strongest source for AI citation if they include machine-readable metadata. Aggregated news indexes and topical feeds increase authoritative overlap by providing independent repeaters. Verified social accounts that link to the canonical page help provenance when the social link uses the same structured metadata. Open-access archives and institutional repositories provide long-term availability and assist in provenance checks. Channels behind paywalls reduce AI citation likelihood because crawlers and data providers often exclude restricted content.
Ensure the primary page uses schema markup, stable URLs, HTTPS, descriptive titles, and direct download links for assets. Provide mirror pages only if they preserve the same metadata and canonical tag.
What measurement methods prove PR impact in AI search?
Measure extraction accuracy, citation frequency in AI answers, snippet placement, time-to-index, and cross-source consistency to prove AI search impact.
Extraction accuracy can be measured by automated checks that compare parsed entities against the release. Citation frequency requires monitoring AI assistant outputs and search engine results for direct referencing of the release URL or quoted facts. Track snippet placement with SERP monitoring tools that report featured snippet presence for target queries. Time-to-index uses timestamp logs from publish time to first crawl and first appearance in knowledge panels or cached snapshots. Cross-source consistency uses reverse-searches to count independent authoritative repeaters that publish identical facts within a set window.
Set up an automated daily report for the first 72 hours after publication showing time-to-first-crawl, first-citation, snippet presence, and number of repeaters quoting core facts.
Where do distributed facts get used by AI systems?
AI systems use distributed facts in search snippets, knowledge panels, voice answers, news summaries, and entity profiles in knowledge graphs.
When AI systems build answers, they aggregate facts from multiple web sources. Distributed facts feed into snippet lines, answer boxes, and summarised timelines used by assistants. Facts that include dates, figures, and named sources often appear in timelines and entity profiles. AI systems also use author metadata to assign credibility scores for conflicting claims. Persistent, machine-readable facts populate long-term knowledge graphs that support future queries.
How does provenance affect AI citation and trust?
Provenance affects citation and trust because AI systems rank sources by verifiability, publication consistency, and archival stability.
Provenance signals include consistent author bylines, stable timestamps, canonical linking, and accessible archives. When multiple independent publishers reproduce the same facts with identical timestamps and consistent metadata, AI systems attach higher credibility scores to those facts. Contradictions reduce citation likelihood and increase the chance of content being filtered or labeled as disputed. Clear provenance reduces ambiguity in entity resolution and decreases time-to-citation.
Use persistent identifiers, include author credentials on the page, and ensure the content is archived in an open repository or web archive.
Explore More Expert Insights:
8 UK Media Gatekeepers Journalists Block by Default in 2026
Why 73% of UK Press Releases Never Get Picked Up
What are practical use cases for AI-optimised PR distribution?
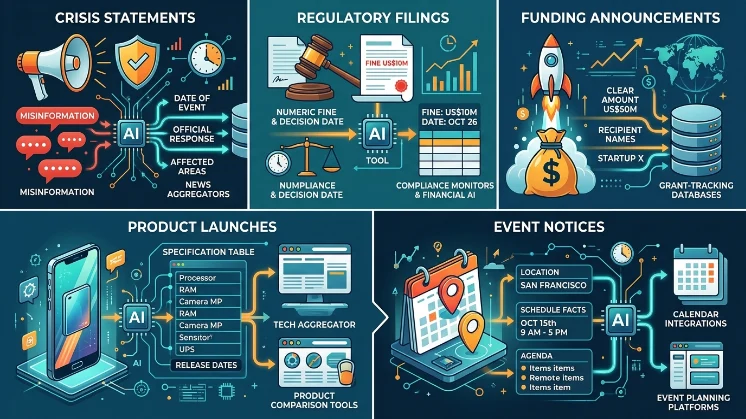
Use cases include crisis statements, regulatory filings, funding announcements, product launches, and event notices where quick, accurate extraction and citation matter.
Crisis statements require rapid, machine-readable facts to prevent misinformation. Regulatory filings need precise dates and numeric data for compliance monitors and financial AI tools. Funding announcements benefit from clear amounts and recipient names for grant databases. Product launches use specification tables and release dates for tech aggregators. Event notices use location and schedule facts for calendar integrations.
A regulatory filing with a numeric fine and decision date will appear verbatim in compliance tools. A funding announcement with clear recipient data will feed grant-tracking databases.
How should teams prepare operationally for AI-era distribution?
Teams should standardise templates, add JSON-LD and schema, train writers on fact-first leads, and set up monitoring for AI citations and snippet appearances.
Create distribution templates that require a 1–2 sentence factual lead with explicit numbers and dates. Integrate schema generation into the content management workflow so every release exports JSON-LD automatically. Train editorial staff on entity normalisation rules and on when to publish corrections with explicit modified timestamps. Implement monitoring tools that capture AI assistant outputs and SERP snippets and report metrics listed earlier.
Adopt templates and schema within 30 days, train staff within 60 days, and implement monitoring with the first pilot campaign within 90 days.
Explore More Expert Insights:
PA Media vs Wire Services: What 500 UK Campaigns Revealed
PR distribution in the AI search era demands machine-readable facts, consistent provenance, and measurable signals. Five core statistics extraction accuracy, citation rate, snippet share, time-to-index, and authoritative overlap—define success. Teams must adopt structured metadata, concise factual leads, and monitoring to ensure release facts feed AI systems reliably and quickly.
Read More for Better Understanding:
Fleet Street to Digital: Which PR Distribution Reaches Both in 2026?


